When using OCR (Optical Character Recognition) to extract text from documents, you may occasionally encounter unexpected white spaces between characters. This typically results from variations in character width and spacing, and unfortunately, applying filters to the input doesn't always resolve the issue.
Based on investigation, the following approaches have proven effective in avoiding extra spaces.
-
Use the Roboto Font
Roboto is a clean, modern typeface that is OCR-friendly and often yields better character recognition results. -
Use
ReadDocumentAdvanced()
This method offers more control over the OCR process and can enhance the handling of complex text layouts. -
Use
OcrLanguage.EnglishBest
This advanced language model provides better accuracy than the standard English option. -
Train a Custom Font
If the input PDF uses a unique or non-standard font, default OCR settings may struggle. Custom font training allows the OCR engine to recognize specific fonts more accurately, significantly improving performance.
Learn how to train a custom font here: OCR Custom Font Training Guide
Before: (Between 7 and 1)
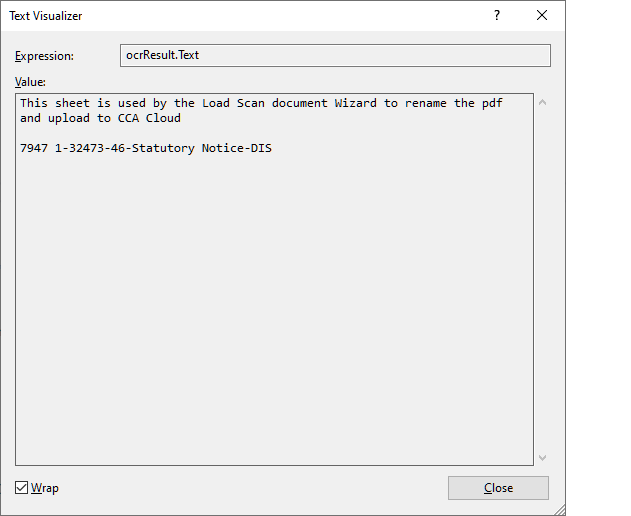
After:
